Extend your L2 Cache with Memcached!
Techs
데이트도 없고 약속도 없는 토요일 네티즌 수사대로서 이런 저런 떡밥을 덥썩 무는 것보다 오늘은 맘먹고 구글링이나 해 봐야지 하는 생각에 이런저런 그리드 관련 문서들을 보다가, 희한한 프로젝트가 있어서 소개한다.
본 프로젝트는, 궁극적으로 컴퓨팅 성능을 memcached 를 사용해 프로세서에 들러붙어있는 L2 Cache를 뻥튀기 함으로서 확장하려는 야심찬, 어떻게 보면 약간의 또라이적( 좋은 의미다 ) 발상으로 시작된 '놀라운 그 무언가' 이다.
요지는, LRU에 무언가의 데이터가 쓰여지기 전에 이 데이터를 memcached 에 먼저 쓰고, 읽기 작업을 할떄도 먼저 읽어서 구현하자는 내용이다.
실제 전체 운영체제에 반영하기에는 매우 힘든 부분이 없지 않으며, 이를 위해서는 리눅스 커널을 만져야 할 필요가 있지만 중요한건 커스터마이징 가능한 어떠한 오픈소스라도 이런 형태의 확장이 가능하지 않겠나 하는것이다.
이 와플그리드 프로젝트는 어떤 DBA의 저녁식사에서 시작되었으며, 개발자가 와플을 좋아해서, 또 본인이 그려놓은 다이어그램이 와플같아서 그렇게 이름 지었다 한다. DBA가 시작한 프로젝트라 그런지 MySQL 의 InnoDB 성능 확장을 프로젝트에서 구현하고 있다.
MySQL 에 InnoDB를 사용하는 분들은 봐 두시면 매우 많은 도움이 되지 않을까 싶다.
이후의 내용은 http://www.bigdbahead.com/?p=73 의 내용을 번역한 것 임을 미리 알려둔다. 번역이 맘에 들지 않더라도 알아서 보시면 되겠고, 못알아 보겠으면 링크의 원문을 보셔도 좋다.
이 프로젝트가 어떤 부분에서는 참 기가막힌 성능을 나타낼 것이고, 다른 부분에 반영하기에 위험이 따르는 것도 사실이므로, 아직은 테스트 정도로 또는 다른 어떤 솔루션을 구현할때의 아이디어 정도로 쓰면 되겠다. 사실 뭐 memcached 의 확장적 사용영역에서 엄청 크게 벗어난 것은 아니니까.
--- Memcached as a L2 Cache for InnoDB - The Waffle Grid Project ---
번역 ( 정윤진, yjjeong@rsupport.com )
몇 달전 힘든 일과 뒤에 목요일 Yves와의 저녁식사에서 어떻게 하면 성능과 확장성을 증가 시킬 수 있을까 하는 논의를 했다. 이 논의에서 나는 그에게 InnoDB를 위한 L2캐쉬로서 memcached 를 사용하면 어떻겠냐는 아이디어를 주었는데, 이 간단한 아이디어는, 뭔가가 LRU 를 참조 할 때마다 memcached 에 데이터셋을 박는 것에서 출발한다.
버퍼에 저장되지 않은 데이터를 디스크에서 읽기전에, memcached 에서 긁어오는 것.
해서 Yves는 메일로 질문질을 하더니, 기어이 골때리게도 실제 0.1 버전의 동작 가능한 프로그램을 보내왔다. 아이디어의 실제 프로젝트화 된 시발점이었달까.
해서 우리는 Waffle Gird 프로젝트라 명명하기로 했다. 왜? 아래의 다이어그램을 보면 와플같이 생기지 않았는가. 게다가 난 와플을 좋아하니까 ( 주: 니가 좋아하니까 그렇게 보이는게 아니냐? ) 또 디게 맛나니까. 뭐 암튼 몇일 밤낮을 홀라당 샌 뒤에, 테스트 가능한 패치코드를 생성 해 냈고, 벤치마크를 시작했다. 동작 했을까? 당근. 게다가 꽤 괜찮았다. 아래의 벤치마크 결과를 참조하시라.
기본적으로, 이 패치를 Central Node 에 적용하고 몇몇의 서버를 remote L cache 로 롤 분배 한다. 예로, 128G 의 메모리를 가진 MySQL 서버 한대와, 각각 64GB 를 가진 4대의 remote 서버를 둔다. 이러한 구성은 전체 256G의 L2 Cache 를 가지게 되겠다. ( 주: 번역을 끝낸뒤에 재검토 해 보니, 이 글에서 말하는 L2 캐쉬는 Remote 노드의 메모리 총합을 말하는 듯 하다. -ㅁ-; L1 캐쉬를 128G 라 하는 것을 보니, Central Node 의 Localhost 의 memcached 영역의 128G 로 잡은 모양인가 보다. 쳇, 내가 구현해서 테스트해봐야지. )
뭐 당연하지만, 보다 빠른 네트워크를 구성하는 경우에 더 빠른 응답을 기대 할 수 있다. 디스크에서 데이터를 가져오는 것보다 훨씬 더-
그림을 까보면 ( 와플같이 생겼다는 ) 이렇다.
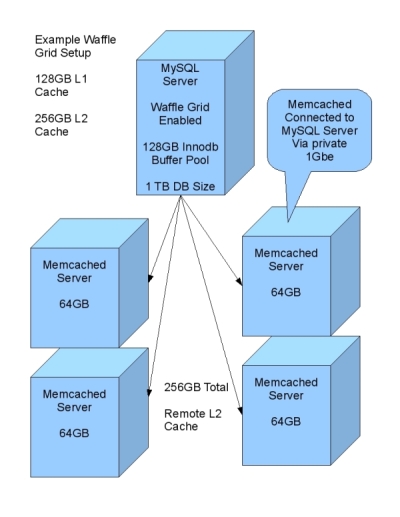
- 우리는 맨날 어떤 클라이언트가 낮은 디스크 성능으로 인해 충분한 역할을 해 내지 못하는지 확인하여야 하며, 이애대한 해결책은 보다 빠른 디스크를 넣거나 또는 메모리를 추가하는 것이다. 하지만 자금상의 문제에 봉착한다거나 서버 한대에 박을 수 있는 메모리 공간이 쫑난다면 어떻게 할 것인가?
- 32비트 제약으로 인한 성능향상. ( 64bit 로의 마이그레이션을 위한 법률 서비스를 제공하는 회사가 있기도 하다 )
- DBRD를 Active/Passive 로 구현하는 경우, Passive 서버에 뭔가 더 역할을 주고 싶어서.
- 친구들이 말하곤 한다. "난 10대의 와플 그리드로 5TB의 메모리 굴린다~"
전술 하였듯이, 동작한다. 근데 니들은 물어보겠지? "쫌 만들었냐? 이거 퍼지는거 아냐?"
벤치마크 결과를 보자.
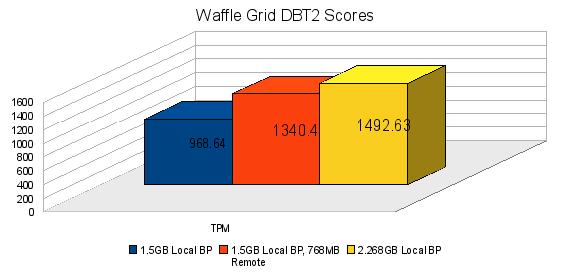
로컬 메모리 ( Central Node 의 ) 를 추가한다면, 더 좋은 성능을 기대 할 수 있다. 하지만 로컬에 더 많은 메모리를 추가 할 수 없는 경우, remote 의 buffer pool 이 답이다. 아무것도 하지 않은 것 보다, Remote Buffer 를 추가 했을 때 38%의 성능 향상이 발생했다. 또 계속 최적화 할 것이므로, 성능은 더 나아질 것으로 기대한다.
해서, Waffle Grid 가 세계의 기아에 대한 솔루션이 될 수 있을 것인가? 아니다.
모든 어플리케이션에 적용 가능 할까? 역시 아니다.
우리는 데이터를 network 에서 읽어오기 때문에, cache miss 나 데이터를 리모트에 넣는데 시간이 걸린다. 근데 만약, 디스크에서 반드시 읽어와야만 하는 데이터가 있는경우, 이에 따른 오버헤드가 매우 커지게 된다. 로컬 캐쉬에서 번저 찾아야 하고 ( OS 로직상 ), 이후 로컬의 memcached 에서 찾고, 다시 remote 의 memcached 에서 찾은 이후에 비로소 디스크를 보게 된다. 이러한 불가결한 로직은 우리가 모르는 동작에 의해 더 늘어 날 수도 있다. 역설하면, 이런 마법같은 상황 ( read-ahead, data accessed from disk sequentially, 아마 빠르겠지 ) 도 발생하지만, 우리는 아직 구현하지 못하고 있다.
추가적인 지연시간은, full table scan 또는 대량의 데이터가 바로 즉시 읽어져야 하는 경우에 발생할 수도 있다. 사실 결과는 일부 커다란 양의 데이터셋에 대한 쿼리의 실행 속도가 5~6배 느려지기도 했다. 이러한 부분의 개선을 위해 계속 작업하고 있으며, 원하는 데이터를 보다 빨리 찾아내기 위해 cache miss 를 줄이는 알고리즘을 개선중이다. 뭐 말하자면, 아직은 개발중인 실험적 코드임에 분명하고, 무결점으로 동작하지 않는다. 이 부분을 피력하려 노력중이며, 이러한 노력이 약속의 반증이라 생각한다. ( 이러지 말자)
SSD는 어떠냐고 물어보시겠지들. SSD로 맛나는 와플을 더 빠르게 할 수 없냐? 대답은, NO 다. 뭐 사실은 나도 SSD로 이런 저런 테스트 해 보았지만, 기대만큼 커다란 향상은 없다. 일반 디스크에 비하면, 약 20% 정도의 향상은 있었다.
더 알고 싶으면, wiki 를 참조하셍. ( http://www.wafflegrid.com/wiki/index.php?title=Main_Page )
---
30분 동안 날림 번역했더니 담배를 피워야 겠다는 사실을 잊고 있었다. 아! 억울해 ㅠ
어떠한 버전의 MySQL 에서 동작하는지는 wiki 에서 찾아보기도 하고 그러시라.
나만 뺑이 칠 순 없잖아.
아, 라이센스는 GNU로 보인다.