httpcfg.exe, forfiles.exe
Techs( 정윤진, bluebird_dba@naver.com )

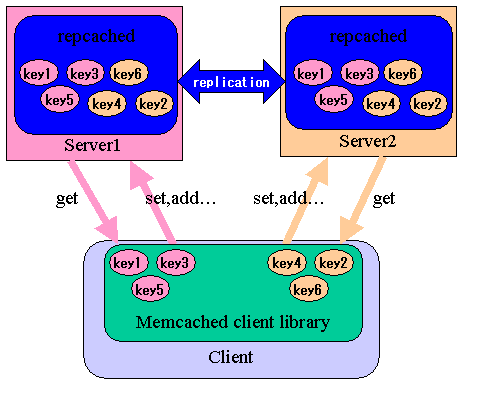
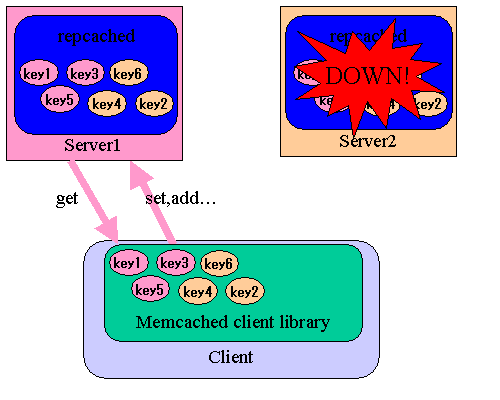
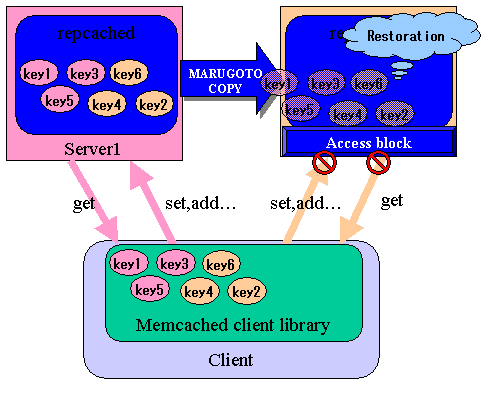
Windows 기반의 서비스를 운용하면서 발생되는 일반적인 이슈중에 하나는, IIS를 구동하면
여러개의 IP를 Aliasing 해서 사용하더라도 절대 80포트를 다른 어플리케이션의 용도로 바인딩 할 수 없다.
이는, IIS 동작 특성상 커널의 http.sys 에서 OS에 할당된 모든 IP를 IIS의 80포트로 바인딩 해 버리기 때문인데 이러한 경우를 대비하여 Support Tool 에서 httpcfg.exe 라는 툴을 제공한다.
뭐 그딴거를 tool 로 지정해? 그냥 유닉스처럼 .cfg 파일에 IP를 지정하면 그걸로 되는거 아니야?
윈도우 못쓰겠구만 하시는 분들은 그냥 계속 유닉스/리눅스 쓰시면 되겠다.
1.1.1.1:80 에는 IIS 를, 2.2.2.2:80 에는 apache 를 바인딩 하고 싶다면,
필수적으로 사용해 주어야 한다.
일단 IIS 가 기동된 상태에서 한번 실행 해 본다.
httpcfg.exe query iplisten -i
결과 값이 어떻게 나타나는지 잘 살펴 본 후에,
이제 IIS 에서 Binding 하여 사용할 IP 를 지정해 준다.
httpcfg.exe set iplisten -i 1.1.1.1
리턴값 0 과 함께 잘 세팅 되었다는 메세지가 나오면, 확인한다.
httpcfg.exe query iplisten -i
만약 잘못 넣었거나, 지우고 싶다면
httpcfg.exe delete iplisten -i 1.1.1.1
설정이 끝나면 IIS 를 재시작 한다.
net stop http /y && net start w3svc
이거 몰라서 한참 헤멘적이 있다. 윈도우에서 제공하는 기본 적인 툴 중에는, 유닉스에서 상식으로 동작하는 것들이 윈도우에서는 수동 설정해 주어야 하는 것들이 많으므로 잘 살펴 보도록 한다.
httpcfg.exe 에 대해서는 다음의 링크를 참조 하도록 한다.
http://technet.microsoft.com/en-us/library/cc787508%28WS.10%29.aspx
비슷한 맥락에서, 리눅스나 유닉스에서 다음과 같은 커맨드를 많이들 사용하실 것이다.
find . -ctime +3 -exec rm -f {}+
이 커맨드는 윈도우에서 다음과 같이 사용 되어 질 수 있다.
forfiles /P C:\Windows\system32\Logfiles\ /M *.log /D -3 /S /C "cmd /c del @file"
아주 기본적인 것들이지만, 이게 안되서 서비스 중지한 경험은 누구나 가지고 있을 것이다.
조금만 더 응용한다면 압축이나 특정 위치로의 Moving 등이 가능하지만.
forfiles 참조
http://technet.microsoft.com/en-us/library/cc753551%28WS.10%29.aspx
굳이 perl 이나 python 을 사용하지 않고도 수행 할 수 있는 시스템 툴들은 알아두는 것이 재산이다. 아주 긴급할때에 요긴하게 사용 할 수 있는 때가 있다.
일례를 들면, 요런거?
root@test$ pwd
/var/log/httpd/
root@test$ du -sh
access.log 4G
root@test$ > access.log
난 참 멍청해서 이런 커맨드 자주 잊어버린다.
( bluebird_dba@naver.com )
A tool
Windows 기반의 서비스를 운용하면서 발생되는 일반적인 이슈중에 하나는, IIS를 구동하면
여러개의 IP를 Aliasing 해서 사용하더라도 절대 80포트를 다른 어플리케이션의 용도로 바인딩 할 수 없다.
이는, IIS 동작 특성상 커널의 http.sys 에서 OS에 할당된 모든 IP를 IIS의 80포트로 바인딩 해 버리기 때문인데 이러한 경우를 대비하여 Support Tool 에서 httpcfg.exe 라는 툴을 제공한다.
뭐 그딴거를 tool 로 지정해? 그냥 유닉스처럼 .cfg 파일에 IP를 지정하면 그걸로 되는거 아니야?
윈도우 못쓰겠구만 하시는 분들은 그냥 계속 유닉스/리눅스 쓰시면 되겠다.
1.1.1.1:80 에는 IIS 를, 2.2.2.2:80 에는 apache 를 바인딩 하고 싶다면,
필수적으로 사용해 주어야 한다.
일단 IIS 가 기동된 상태에서 한번 실행 해 본다.
httpcfg.exe query iplisten -i
결과 값이 어떻게 나타나는지 잘 살펴 본 후에,
이제 IIS 에서 Binding 하여 사용할 IP 를 지정해 준다.
httpcfg.exe set iplisten -i 1.1.1.1
리턴값 0 과 함께 잘 세팅 되었다는 메세지가 나오면, 확인한다.
httpcfg.exe query iplisten -i
만약 잘못 넣었거나, 지우고 싶다면
httpcfg.exe delete iplisten -i 1.1.1.1
설정이 끝나면 IIS 를 재시작 한다.
net stop http /y && net start w3svc
이거 몰라서 한참 헤멘적이 있다. 윈도우에서 제공하는 기본 적인 툴 중에는, 유닉스에서 상식으로 동작하는 것들이 윈도우에서는 수동 설정해 주어야 하는 것들이 많으므로 잘 살펴 보도록 한다.
httpcfg.exe 에 대해서는 다음의 링크를 참조 하도록 한다.
http://technet.microsoft.com/en-us/library/cc787508%28WS.10%29.aspx
비슷한 맥락에서, 리눅스나 유닉스에서 다음과 같은 커맨드를 많이들 사용하실 것이다.
find . -ctime +3 -exec rm -f {}+
이 커맨드는 윈도우에서 다음과 같이 사용 되어 질 수 있다.
forfiles /P C:\Windows\system32\Logfiles\ /M *.log /D -3 /S /C "cmd /c del @file"
아주 기본적인 것들이지만, 이게 안되서 서비스 중지한 경험은 누구나 가지고 있을 것이다.
조금만 더 응용한다면 압축이나 특정 위치로의 Moving 등이 가능하지만.
forfiles 참조
http://technet.microsoft.com/en-us/library/cc753551%28WS.10%29.aspx
굳이 perl 이나 python 을 사용하지 않고도 수행 할 수 있는 시스템 툴들은 알아두는 것이 재산이다. 아주 긴급할때에 요긴하게 사용 할 수 있는 때가 있다.
일례를 들면, 요런거?
root@test$ pwd
/var/log/httpd/
root@test$ du -sh
access.log 4G
root@test$ > access.log
난 참 멍청해서 이런 커맨드 자주 잊어버린다.
( bluebird_dba@naver.com )